Data Sovereignty: Private LLMs vs. Public Cloud APIs
Navigate the data sovereignty dilemma in enterprise AI. Compare the risks of public cloud LLM APIs against the security of hosting private, open-weight models on-premise.

Introduction: The New Perimeter is the Prompt
For the modern IT architect, the push to integrate Generative AI into enterprise workflows represents a massive architectural dilemma. On one hand, utilizing Public Cloud APIs (such as OpenAI’s GPT-4 or Anthropic’s Claude) offers immediate access to state-of-the-art intelligence with zero infrastructure overhead. On the other hand, feeding proprietary corporate data, customer PII, and trade secrets into a third-party API fundamentally breaks the traditional security perimeter — a phenomenon often exacerbated by Shadow AI adoption across departments.
This conflict lies at the heart of Data Sovereignty—the concept that data is subject to the laws and governance structures of the nation or region in which it is collected and processed. As global privacy regulations tighten, organizations are increasingly forced to choose between the raw power of public AI and the strict compliance of Private LLMs hosted within their own infrastructure.
1. The Compliance Risks of Public Cloud APIs
When an application sends a prompt to a public LLM API, the data leaves the organization’s Virtual Private Cloud (VPC), travels across the public internet, and is processed on the vendor’s servers. Even with enterprise agreements that promise data encryption in transit and at rest, this architecture introduces severe geopolitical and regulatory risks.
- Cross-Border Data Transfers: Under regulations like the GDPR in Europe or the CCPA in California, transferring personal data across national borders to a foreign AI processing center can be a direct violation of compliance. If a French hospital uses a US-hosted API to summarize patient notes, the data sovereignty of those health records is compromised.
- The CLOUD Act vs. GDPR: In the United States, the CLOUD Act allows federal law enforcement to compel US-based tech companies to provide requested data stored on their servers, regardless of whether those servers are located in the US or Europe. This creates a fundamental legal clash for European companies relying on American AI vendors, driving the need for localized, sovereign solutions.
2. The Rise of Private, Open-Weight LLMs
To regain control over their data, enterprises are turning to Private LLMs. This movement has been radically accelerated by the open-source and “open-weight” community, led by models like Meta’s Llama, France’s Mistral AI, and UAE’s Falcon.
Instead of leasing intelligence via an API, an organization downloads the model weights and hosts the AI entirely within its own secure perimeter (either on bare-metal servers on-premise or within an isolated, region-specific cloud VPC).
- Absolute Data Sovereignty: Because the model runs locally, the data never leaves the organization’s control. A prompt containing highly classified financial data is processed on internal hardware, mathematically guaranteeing that the information cannot be intercepted by foreign entities or used to train a third-party vendor’s future models.
- Custom Fine-Tuning: Hosting a private model allows IT teams to deeply fine-tune the AI on highly specific, proprietary corporate data without risking intellectual property leakage. The resulting model becomes a highly specialized, highly secure internal asset.
3. The Hidden Costs of Going Private
While Private LLMs solve the data sovereignty problem, they introduce massive infrastructural and operational challenges that IT managers must account for.
- The Hardware Bottleneck: LLMs require massive amounts of GPU VRAM for both training and inference (running the model). Procuring and maintaining enterprise-grade GPUs (like NVIDIA H100s) is incredibly expensive and subject to global supply chain shortages.
- The Talent Gap: Managing a public API takes a few lines of code. Deploying, scaling, and securing a private LLM cluster requires specialized MLOps (Machine Learning Operations) engineers who can optimize model quantization, manage vector databases, and handle containerized GPU orchestration.
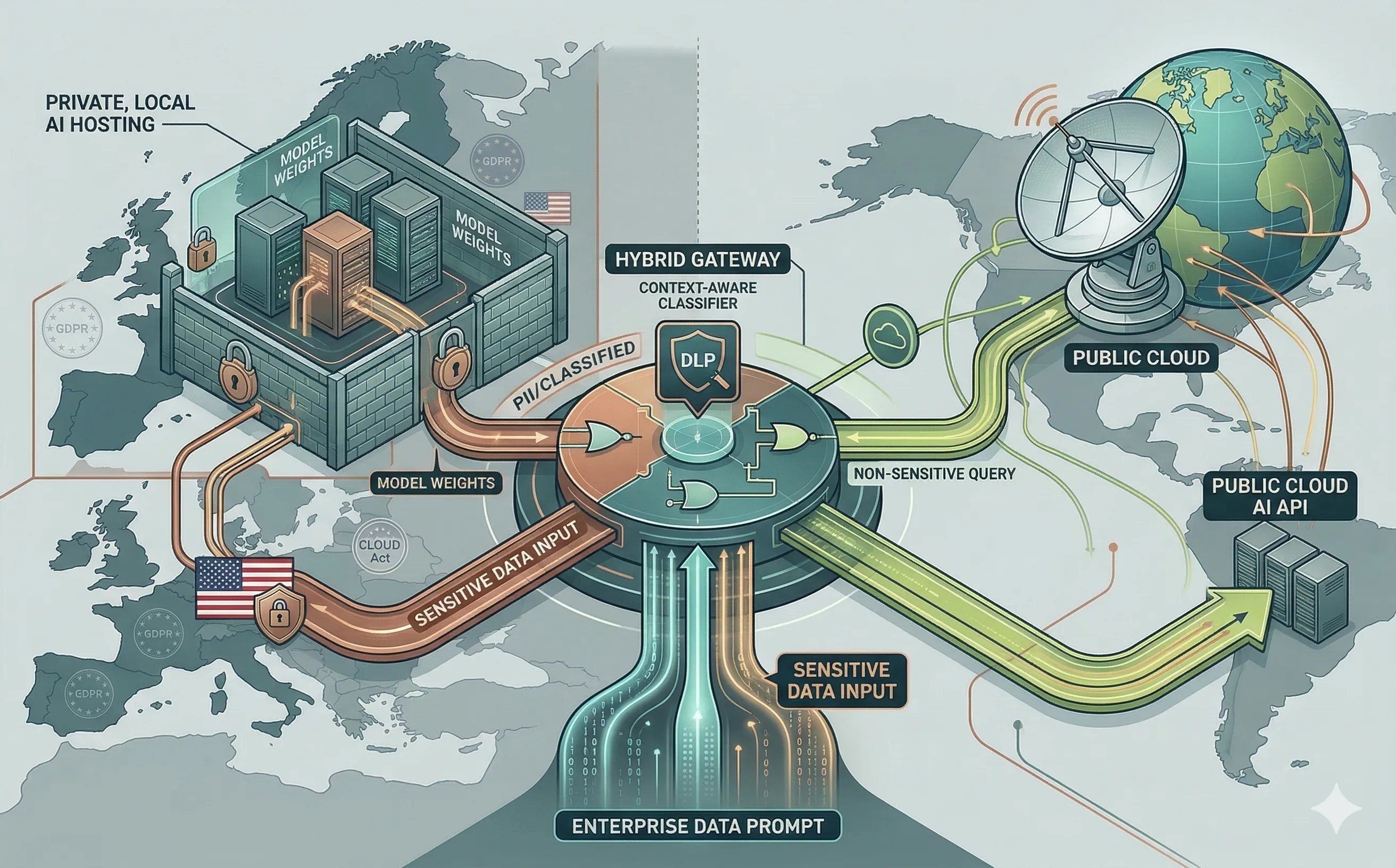
4. The Strategic Compromise: Hybrid AI Routing
For most enterprises, a binary choice between public and private is inefficient. The most pragmatic architectural strategy emerging in the industry is the Hybrid AI Gateway.
A Hybrid AI Gateway sits between the corporate applications and the AI models, acting as an intelligent, context-aware router.
- Data Classification in Real-Time: When a user submits a prompt, the gateway analyzes the payload. If the prompt contains non-sensitive queries (e.g., “Write a Python script to sort an array”), the gateway routes it to the cheaper, faster Public Cloud API.
- Sovereign Routing: If the gateway’s Data Loss Prevention (DLP) scanner detects PII, financial data, or classified internal project names, it intercepts the request and automatically routes it to the internal, Private LLM.
Conclusion
Data sovereignty is no longer an abstract legal concept; it is a hard architectural constraint. While Public Cloud APIs will continue to drive general-purpose AI adoption, the future of enterprise cybersecurity relies on the ability to process sensitive data internally. As we explore in our article on the Splinternet, these geopolitical pressures are only intensifying. By understanding the risks of cross-border data transfer and implementing hybrid routing architectures, IT leaders can harness the power of artificial intelligence without surrendering their sovereign data.