The Risk of "Hallucinated" Vulnerabilities: False Positives in Audits
Discover the hidden costs of AI-driven code audits. Learn why LLMs hallucinate vulnerabilities and how reachability analysis grounds AI in deterministic truth.

Introduction: When the Oracle Lies
The cybersecurity industry is aggressively integrating Large Language Models (LLMs) into code auditing and penetration testing tools. The pitch is compelling: point an AI at your repository, and it will instantly read millions of lines of code, identifying complex logic flaws that traditional SAST and DAST misses.
While AI excels at finding deeply buried contextual bugs, it introduces a dangerous new phenomenon into the DevSecOps pipeline: the Hallucinated Vulnerability. Because LLMs are probabilistic pattern-matchers rather than deterministic compilers, they frequently invent security flaws that do not actually exist. If security teams treat AI-generated audit reports as absolute truth, they risk overwhelming their developers with phantom bugs, destroying trust in the security program, and paralyzing the release cycle.
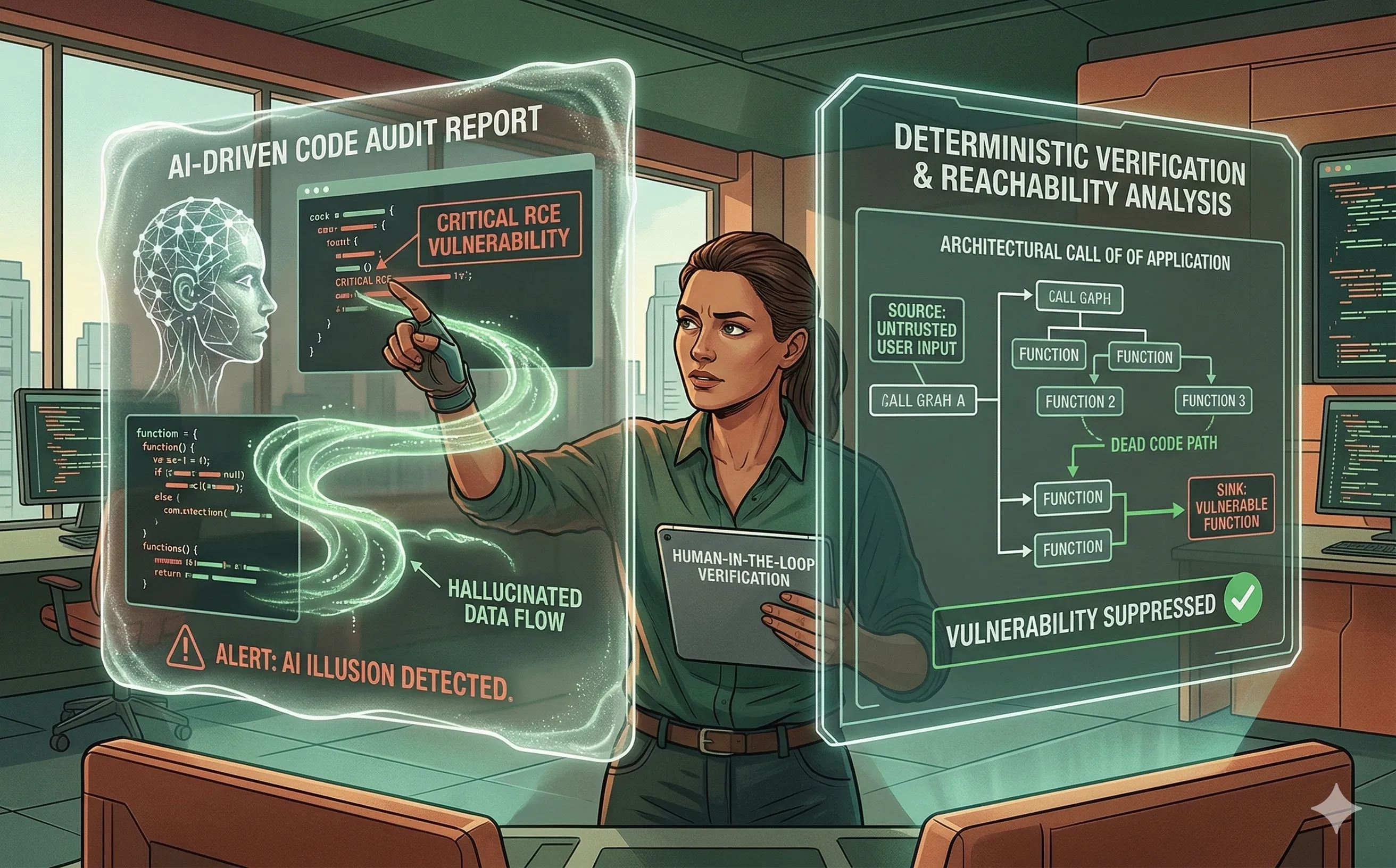
1. The Mechanics of a Security Hallucination
To understand why an AI hallucinates a vulnerability, we must remember how it “reads” code. An LLM does not compile the software, nor does it execute it in memory. It predicts tokens based on its training data.
- Contextual Blindness: An AI might analyze a Python script and see the
eval()orsubprocess.Popen()function. In its training data, these functions are heavily associated with Remote Code Execution (RCE) vulnerabilities. The AI immediately flags it as a “Critical RCE.” However, it fails to realize that the input passed to that function is completely hardcoded, sanitized, and inaccessible to any external user. - Invented Attack Vectors: In more extreme cases, an LLM might hallucinate entire data flow paths. It might claim that a user input from a frontend web form flows directly into a backend SQL query, completely ignoring the robust middleware sanitization layer that intercepts the request in a different file.
2. The True Cost: Alert Fatigue on Steroids
DevSecOps teams are already fighting a losing battle against alert fatigue. Legacy security scanners generate thousands of false positives. The promise of AI was to reduce this noise by adding context.
When an AI hallucinates, it actually creates a worse form of alert fatigue. A legacy SAST false positive is usually easy for a developer to dismiss because it’s a dumb, rigid rule. An AI-hallucinated vulnerability, however, is presented with a highly convincing, articulate, and completely fabricated narrative. The AI will generate a detailed (but physically impossible) exploit chain. Developers are forced to waste hours reverse-engineering the AI’s logic, only to discover the entire scenario was a ghost. Once a developer wastes an afternoon chasing an AI hallucination, they will likely ignore the AI’s real findings the next day.
3. The Antidote: Deterministic Verification and Reachability
You cannot fix AI hallucinations with more AI; you must ground the probabilistic model in deterministic reality. The most effective way to validate an AI’s security claim is to pair it with Reachability Analysis.
Reachability analysis uses deterministic parsing to build a Call Graph of the application.
- The Workflow: The AI scans the code and flags a potential vulnerability (e.g., a vulnerable open-source library function). Before the alert is ever shown to a human, the DevSecOps pipeline runs a reachability scan.
- The Validation: The deterministic engine asks: “Is there an actual execution path from an untrusted user input (the source) to this vulnerable function (the sink)?” If the vulnerable function is dead code, or if it is only ever called by an internal, secure administrative process, the system automatically suppresses the AI’s hallucinated alert.
4. Designing the Human-in-the-Loop (HITL) Audit
Relying entirely on autonomous AI agents to gate your CI/CD pipeline is currently a recipe for disaster. Effective AI code auditing requires strict Human-in-the-Loop (HITL) guardrails.
- AI as a Pointer, Not a Judge: Security architects must treat LLMs like highly eager, slightly unreliable junior analysts — similar to the mindset required when using AI coding assistants like Copilot securely. The AI’s job is to point out areas of interest and highlight complex logic that warrants human review, not to make the final “pass/fail” decision on a build.
- Prompting for Evidence: When integrating LLMs into custom DevSecOps workflows, security teams must engineer their prompts to demand proof. Instead of asking, “Are there any vulnerabilities?” the prompt should be: “Identify potential data flow vulnerabilities. For every vulnerability found, you must output the exact file path, line numbers, and trace the execution flow from source to sink. If you cannot trace the flow, do not report the vulnerability.” Forcing the LLM to show its work drastically reduces its tendency to invent flaws.
Conclusion
Artificial Intelligence is an incredibly powerful magnifying glass for code auditing, capable of spotting semantic logic flaws that traditional regex scanners could never comprehend. But a magnifying glass cannot replace the eye of the inspector. By understanding the mechanical limitations of LLMs, pairing them with deterministic reachability analysis, and maintaining human oversight, organizations can harness the speed of AI audits without falling victim to its illusions.