Le risque des vulnérabilités "hallucinées" : les faux positifs dans les audits
Découvrez les coûts cachés des audits de code pilotés par l'IA. Apprenez pourquoi les LLM hallucinent des vulnérabilités et comment l'analyse d'accessibilité ancre l'IA dans la réalité déterministe.

Introduction : quand l’oracle ment
L’industrie de la cybersécurité intègre agressivement les grands modèles de langage (LLM) dans les outils d’audit de code et de tests de pénétration. L’argument est séduisant : pointez une IA vers votre dépôt, et elle lira instantanément des millions de lignes de code en identifiant des failles logiques complexes que les outils traditionnels SAST et DAST manquent.
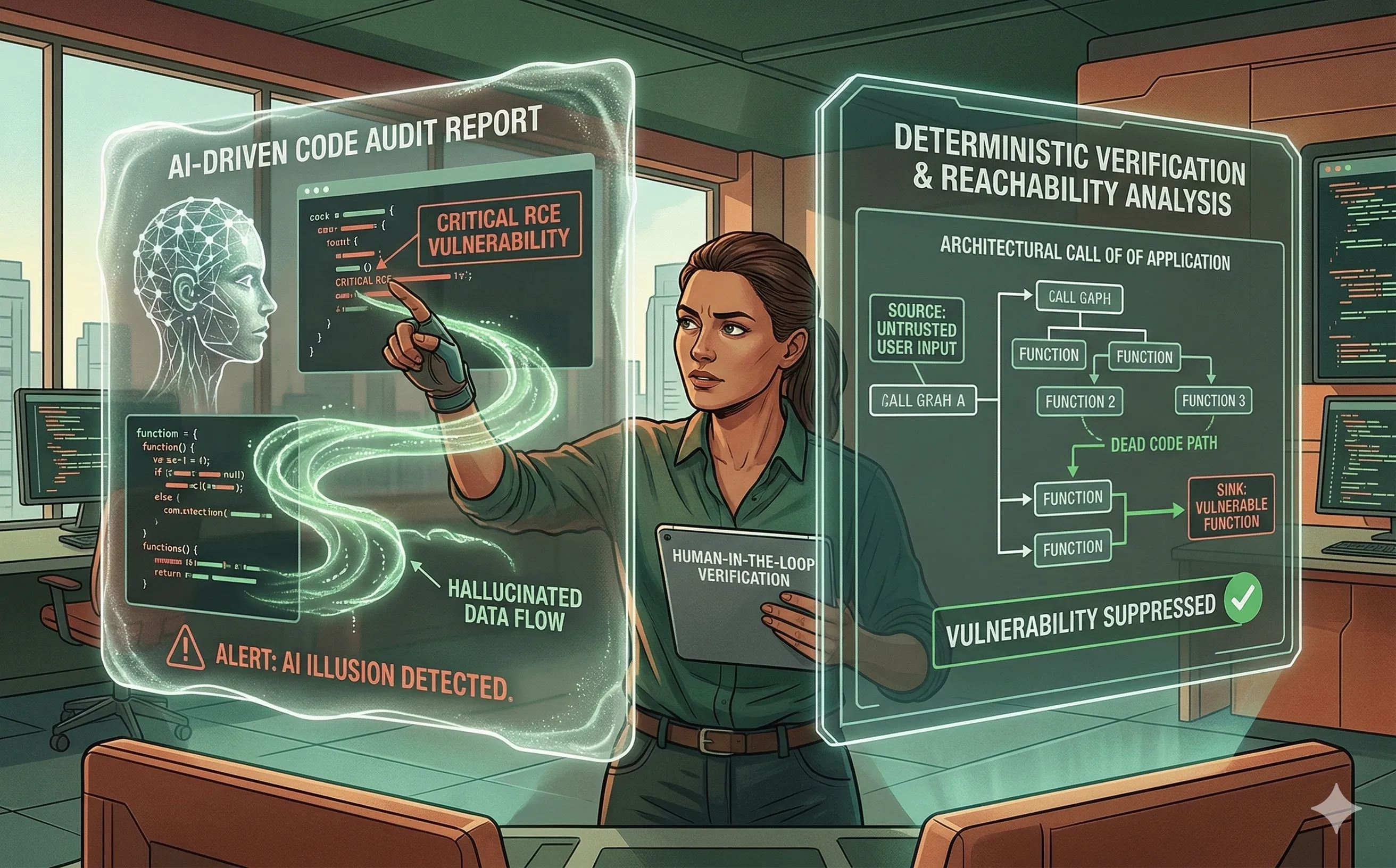
Si l’IA excelle à trouver des bugs contextuels profondément enfouis, elle introduit un phénomène dangereux et inédit dans le pipeline DevSecOps : la vulnérabilité hallucinée. Parce que les LLM sont des systèmes de correspondance probabiliste de patterns plutôt que des compilateurs déterministes, ils inventent fréquemment des failles de sécurité qui n’existent pas réellement. Si les équipes de sécurité traitent les rapports d’audit générés par l’IA comme une vérité absolue, elles risquent de submerger leurs développeurs de bugs fantômes, de détruire la confiance dans le programme de sécurité et de paralyser le cycle de publication.
1. La mécanique d’une hallucination de sécurité
Pour comprendre pourquoi une IA hallucine une vulnérabilité, nous devons nous rappeler comment elle « lit » le code. Un LLM ne compile pas le logiciel, ne l’exécute pas en mémoire. Il prédit des tokens à partir de ses données d’entraînement.
- Cécité contextuelle : Une IA peut analyser un script Python et voir la fonction
eval()ousubprocess.Popen(). Dans ses données d’entraînement, ces fonctions sont fortement associées aux vulnérabilités d’exécution de code à distance (RCE). L’IA la signale immédiatement comme une « RCE critique ». Cependant, elle ne réalise pas que l’entrée passée à cette fonction est entièrement codée en dur, assainie et inaccessible à tout utilisateur externe. - Vecteurs d’attaque inventés : Dans des cas plus extrêmes, un LLM peut halluciner des chemins de flux de données entiers. Il peut affirmer qu’une entrée utilisateur provenant d’un formulaire web frontend aboutit directement dans une requête SQL backend, ignorant complètement la couche d’assainissement middleware robuste qui intercepte la requête dans un autre fichier.
2. Le vrai coût : la fatigue d’alerte à la puissance maximale
Les équipes DevSecOps livrent déjà une bataille difficile contre la fatigue d’alerte. Les scanners de sécurité legacy génèrent des milliers de faux positifs. La promesse de l’IA était de réduire ce bruit en ajoutant du contexte.
Quand une IA hallucine, elle crée en réalité une forme encore pire de fatigue d’alerte. Un faux positif d’un SAST legacy est généralement facile à écarter pour un développeur, car il s’agit d’une règle rigide et simpliste. Une vulnérabilité hallucinée par une IA, en revanche, est présentée avec un récit très convaincant, articulé et totalement fabriqué. L’IA générera une chaîne d’exploitation détaillée (mais physiquement impossible). Les développeurs sont contraints de passer des heures à décortiquer la logique de l’IA, pour découvrir que tout le scénario était un fantôme. Lorsqu’un développeur perd un après-midi à chasser une hallucination d’IA, il ignorera probablement les vraies découvertes de l’IA le lendemain.
3. L’antidote : la vérification déterministe et l’analyse d’accessibilité
On ne peut pas corriger les hallucinations de l’IA avec davantage d’IA ; il faut ancrer le modèle probabiliste dans la réalité déterministe. La façon la plus efficace de valider une affirmation de sécurité d’une IA est de la combiner avec une analyse d’accessibilité (Reachability Analysis).
L’analyse d’accessibilité utilise un parsing déterministe pour construire un graphe d’appel de l’application.
- Le flux de travail : L’IA analyse le code et signale une vulnérabilité potentielle (par exemple, une fonction de bibliothèque open source vulnérable). Avant que l’alerte ne soit jamais présentée à un humain, le pipeline DevSecOps lance une analyse d’accessibilité.
- La validation : Le moteur déterministe demande : « Existe-t-il un chemin d’exécution réel depuis une entrée utilisateur non fiable (la source) vers cette fonction vulnérable (le sink) ? » Si la fonction vulnérable est du code mort, ou si elle n’est appelée que par un processus administratif interne et sécurisé, le système supprime automatiquement l’alerte hallucinée de l’IA.
4. Concevoir l’audit avec supervision humaine (HITL)
S’appuyer entièrement sur des agents IA autonomes pour contrôler votre pipeline CI/CD est actuellement une recette pour le désastre. Un audit de code IA efficace exige des garde-fous stricts avec supervision humaine (Human-in-the-Loop, HITL).
- L’IA comme pointeur, pas comme juge : Les architectes de sécurité doivent traiter les LLM comme des analystes juniors très zélés mais légèrement peu fiables — un état d’esprit similaire à celui requis pour utiliser les assistants de code IA comme Copilot de manière sécurisée. Le rôle de l’IA est d’indiquer des zones d’intérêt et de mettre en évidence des logiques complexes nécessitant une révision humaine, et non de prendre la décision finale de « valider/rejeter » un build.
- Exiger des preuves dans les prompts : Lors de l’intégration de LLM dans des flux de travail DevSecOps personnalisés, les équipes de sécurité doivent concevoir leurs prompts pour exiger des preuves. Plutôt que de demander « Y a-t-il des vulnérabilités ? », le prompt devrait être : « Identifiez les vulnérabilités potentielles de flux de données. Pour chaque vulnérabilité trouvée, vous devez indiquer le chemin de fichier exact, les numéros de ligne et tracer le flux d’exécution de la source au sink. Si vous ne pouvez pas tracer le flux, ne signalez pas la vulnérabilité. » Forcer le LLM à montrer son raisonnement réduit considérablement sa tendance à inventer des failles.
Conclusion
L’intelligence artificielle est une loupe incroyablement puissante pour l’audit de code, capable de repérer des failles logiques sémantiques que les scanners regex traditionnels ne pourraient jamais comprendre. Mais une loupe ne peut pas remplacer l’œil de l’inspecteur. En comprenant les limites mécaniques des LLM, en les combinant avec une analyse d’accessibilité déterministe et en maintenant une supervision humaine, les organisations peuvent exploiter la rapidité des audits IA sans en devenir les victimes.