Souveraineté des données : LLM privés vs APIs cloud publiques
Naviguez dans le dilemme de la souveraineté des données dans l'IA d'entreprise. Comparez les risques des APIs LLM cloud publiques avec la sécurité de l'hébergement de modèles open-weight privés sur site.

Introduction : le nouveau périmètre, c’est le prompt
Pour l’architecte informatique moderne, la pression d’intégrer l’IA générative dans les workflows d’entreprise représente un dilemme architectural majeur. D’un côté, utiliser les APIs cloud publiques (comme GPT-4 d’OpenAI ou Claude d’Anthropic) offre un accès immédiat à une intelligence de pointe sans aucune infrastructure à gérer. De l’autre, alimenter une API tierce avec des données d’entreprise propriétaires, des données personnelles clients et des secrets commerciaux rompt fondamentalement le périmètre de sécurité traditionnel — un phénomène souvent exacerbé par l’adoption du Shadow AI au sein des départements.
Ce conflit est au cœur de la souveraineté des données — le concept selon lequel les données sont soumises aux lois et aux structures de gouvernance de la nation ou de la région dans laquelle elles sont collectées et traitées. À mesure que les réglementations mondiales sur la vie privée se renforcent, les organisations sont de plus en plus contraintes de choisir entre la puissance brute de l’IA publique et la conformité stricte des LLM privés hébergés dans leur propre infrastructure.
1. Les risques de conformité des APIs cloud publiques
Lorsqu’une application envoie un prompt à une API LLM publique, les données quittent le Virtual Private Cloud (VPC) de l’organisation, transitent par l’internet public et sont traitées sur les serveurs du fournisseur. Même avec des accords d’entreprise promettant le chiffrement des données en transit et au repos, cette architecture introduit de graves risques géopolitiques et réglementaires.
- Transferts de données transfrontaliers : En vertu de réglementations comme le RGPD en Europe ou le CCPA en Californie, le transfert de données personnelles vers un centre de traitement IA étranger peut constituer une violation directe de la conformité. Si un hôpital français utilise une API hébergée aux États-Unis pour résumer des notes de patients, la souveraineté des données de ces dossiers de santé est compromise.
- Le CLOUD Act vs le RGPD : Aux États-Unis, le CLOUD Act permet aux forces de l’ordre fédérales de contraindre les entreprises technologiques américaines à fournir des données demandées stockées sur leurs serveurs, quel que soit l’emplacement de ces serveurs. Cela crée un conflit juridique fondamental pour les entreprises européennes qui s’appuient sur des fournisseurs d’IA américains, renforçant le besoin de solutions localisées et souveraines.
2. L’essor des LLM privés open-weight
Pour reprendre le contrôle de leurs données, les entreprises se tournent vers les LLM privés. Ce mouvement a été radicalement accéléré par la communauté open-source et « open-weight », portée par des modèles comme Llama de Meta, Mistral AI en France et Falcon des Émirats arabes unis.
Au lieu de louer une intelligence via une API, une organisation télécharge les poids du modèle et héberge l’IA entièrement dans son propre périmètre sécurisé (soit sur des serveurs bare-metal sur site, soit dans un VPC cloud isolé et spécifique à une région).
- Souveraineté des données absolue : Comme le modèle s’exécute localement, les données ne quittent jamais le contrôle de l’organisation. Un prompt contenant des données financières hautement confidentielles est traité sur du matériel interne, garantissant mathématiquement que l’information ne peut pas être interceptée par des entités étrangères ou utilisée pour entraîner les futurs modèles d’un fournisseur tiers.
- Fine-tuning personnalisé : Héberger un modèle privé permet aux équipes informatiques de fine-tuner l’IA en profondeur sur des données d’entreprise propriétaires très spécifiques sans risquer de fuite de propriété intellectuelle. Le modèle résultant devient un actif interne hautement spécialisé et hautement sécurisé.
3. Les coûts cachés du passage au privé
Bien que les LLM privés résolvent le problème de la souveraineté des données, ils introduisent des défis infrastructurels et opérationnels massifs que les responsables informatiques doivent prendre en compte.
- Le goulot d’étranglement matériel : Les LLMs nécessitent d’importantes quantités de VRAM GPU pour l’entraînement et l’inférence (exécution du modèle). L’acquisition et la maintenance de GPUs de niveau entreprise (comme les NVIDIA H100) sont incroyablement coûteuses et soumises aux pénuries mondiales de la chaîne d’approvisionnement.
- Le déficit de compétences : Gérer une API publique nécessite quelques lignes de code. Déployer, faire évoluer et sécuriser un cluster de LLM privé requiert des ingénieurs MLOps (Machine Learning Operations) spécialisés capables d’optimiser la quantification des modèles, de gérer des bases de données vectorielles et de gérer l’orchestration GPU conteneurisée.
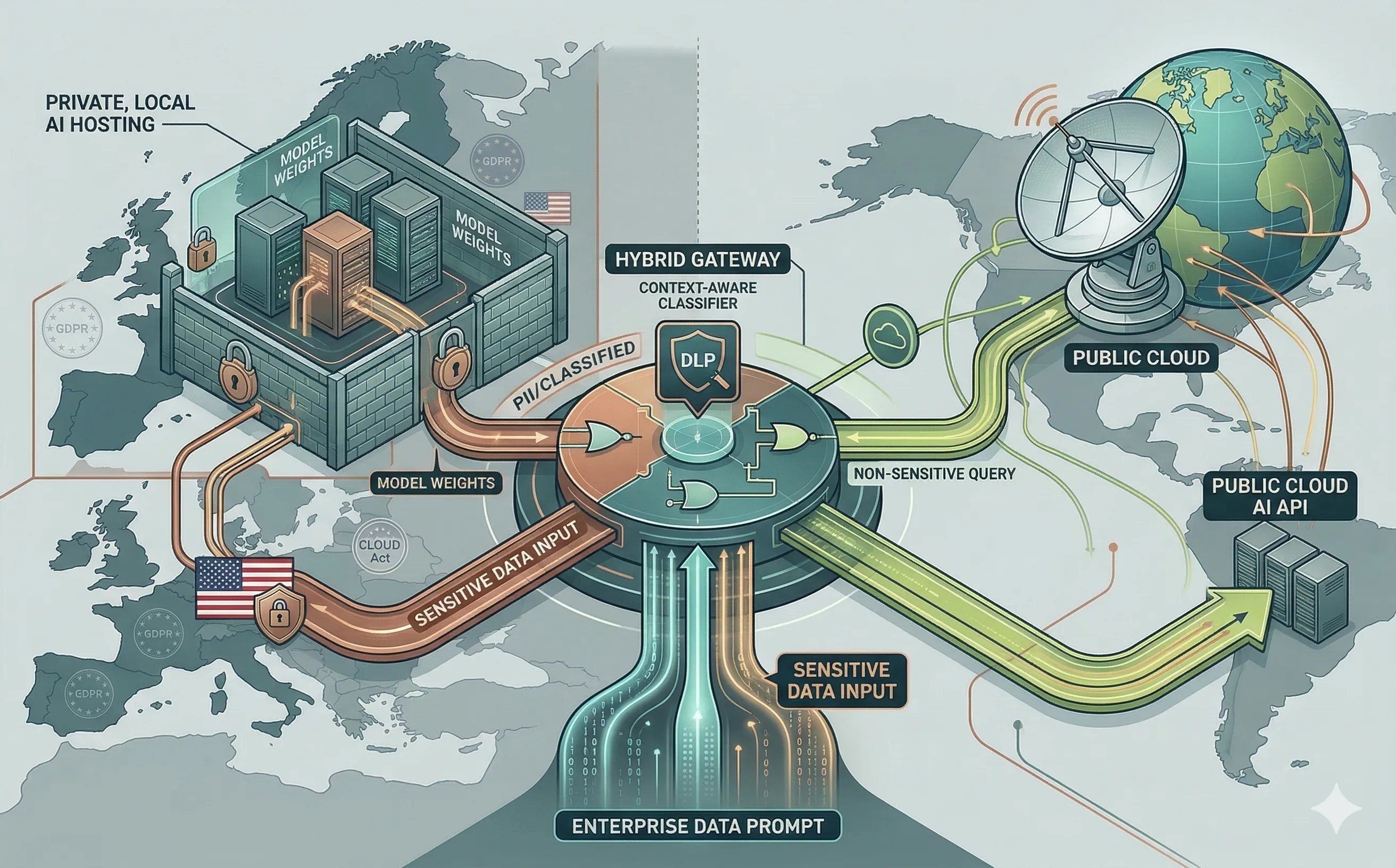
4. Le compromis stratégique : le routage IA hybride
Pour la plupart des entreprises, un choix binaire entre public et privé est inefficace. La stratégie architecturale la plus pragmatique qui émerge dans l’industrie est la passerelle IA hybride.
Une passerelle IA hybride s’intercale entre les applications d’entreprise et les modèles d’IA, agissant comme un routeur intelligent et contextuel.
- Classification des données en temps réel : Lorsqu’un utilisateur soumet un prompt, la passerelle analyse le payload. Si le prompt contient des requêtes non sensibles (par exemple, « Écrire un script Python pour trier un tableau »), la passerelle le route vers l’API cloud publique moins chère et plus rapide.
- Routage souverain : Si le scanner DLP (Data Loss Prevention) de la passerelle détecte des données personnelles, des données financières ou des noms de projets internes classifiés, il intercepte la requête et la route automatiquement vers le LLM privé interne.
Conclusion
La souveraineté des données n’est plus un concept juridique abstrait ; c’est une contrainte architecturale concrète. Si les APIs cloud publiques continueront à stimuler l’adoption de l’IA grand public, l’avenir de la cybersécurité d’entreprise repose sur la capacité à traiter les données sensibles en interne. Comme nous l’explorons dans notre article sur le Splinternet, ces pressions géopolitiques ne font que s’intensifier. En comprenant les risques du transfert de données transfrontalier et en mettant en œuvre des architectures de routage hybride, les responsables informatiques peuvent exploiter la puissance de l’intelligence artificielle sans sacrifier leur souveraineté des données.